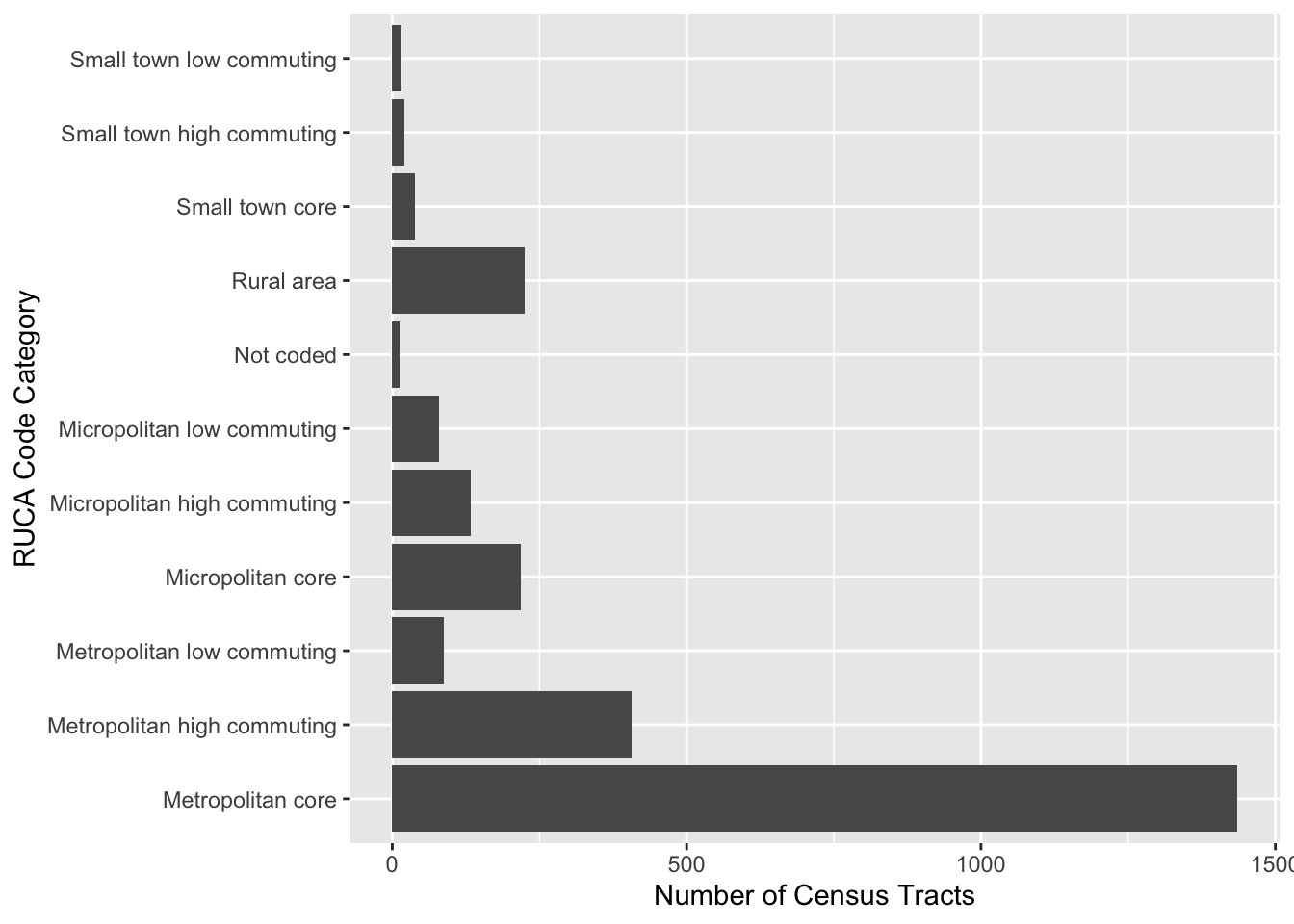
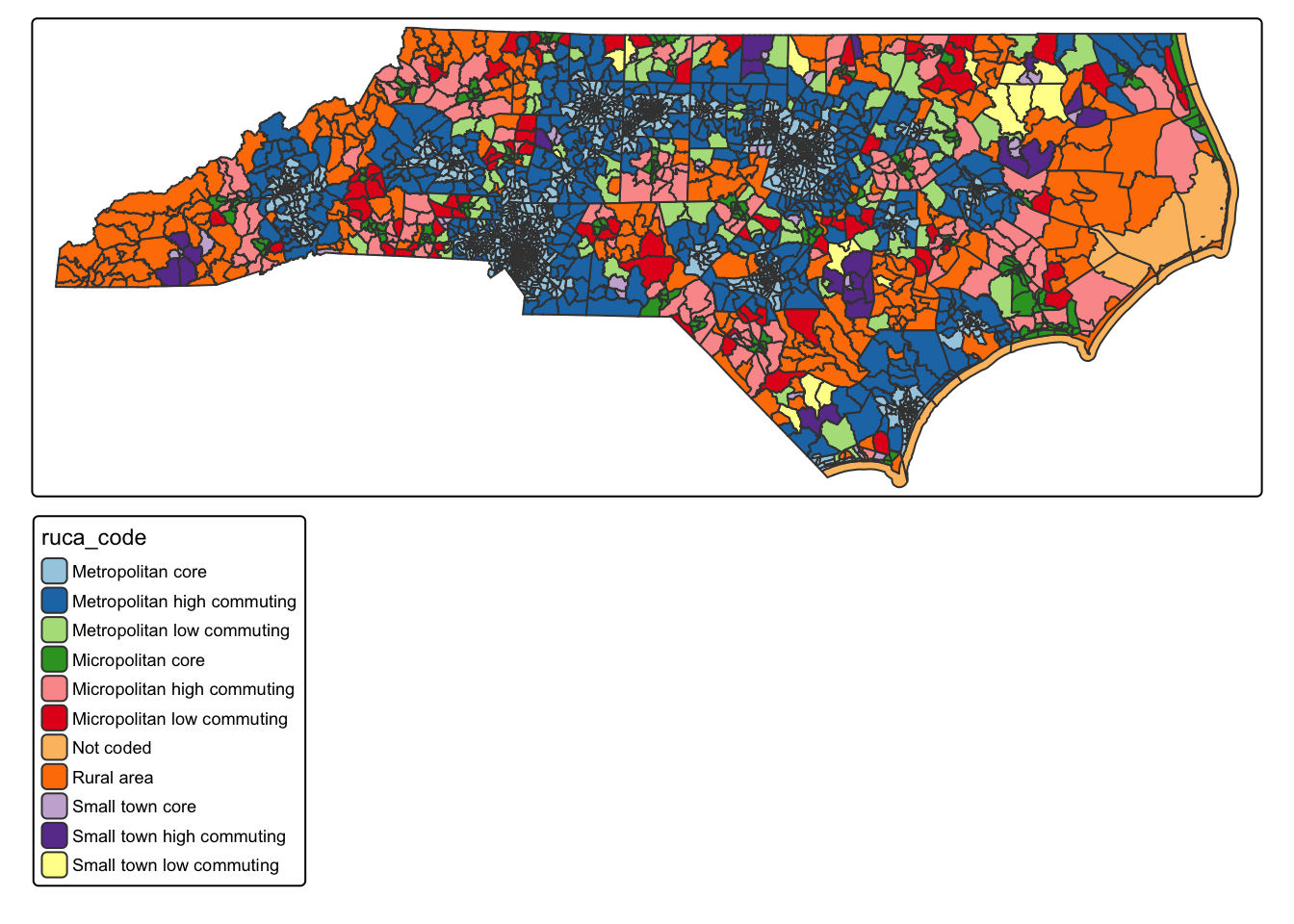
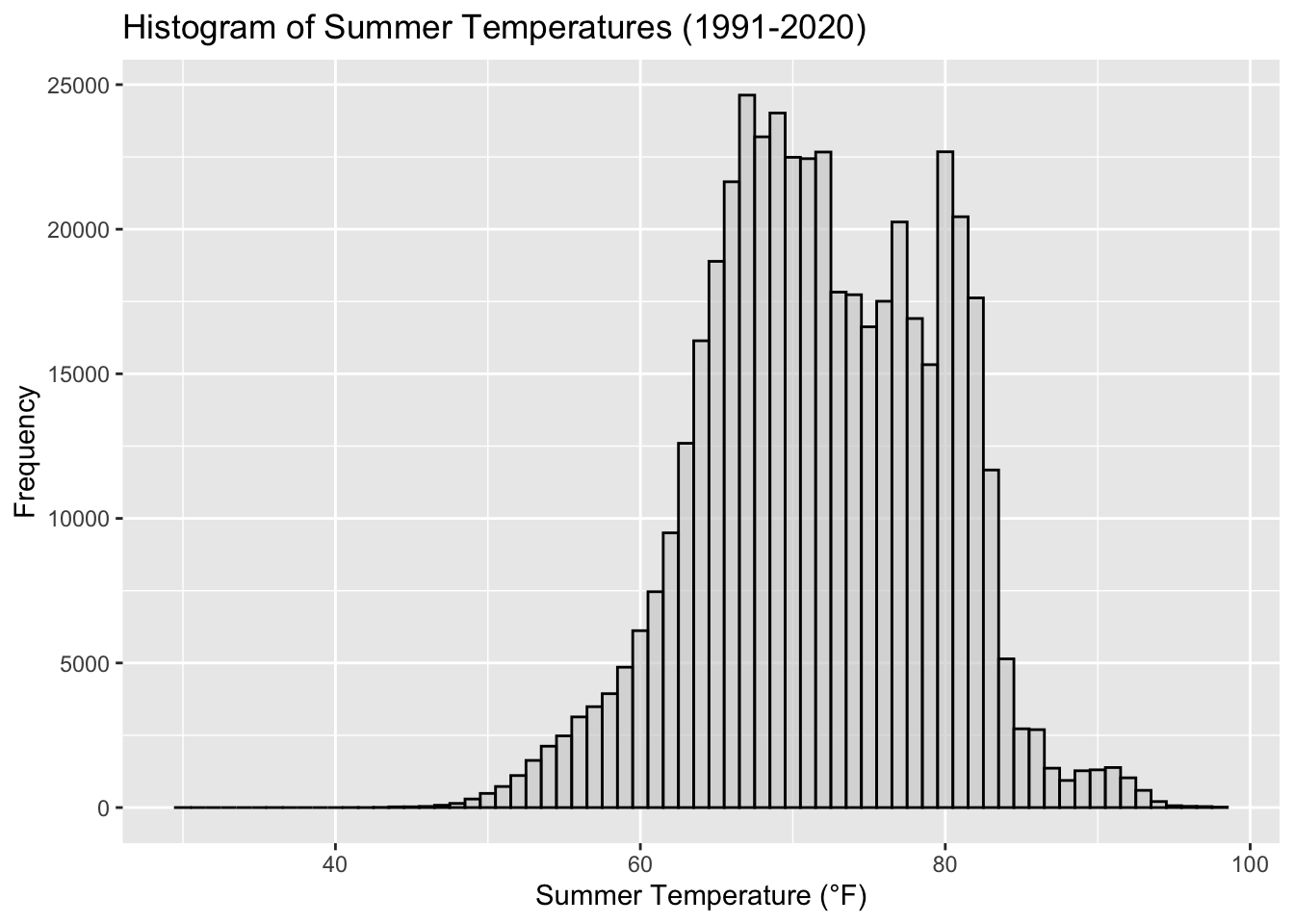
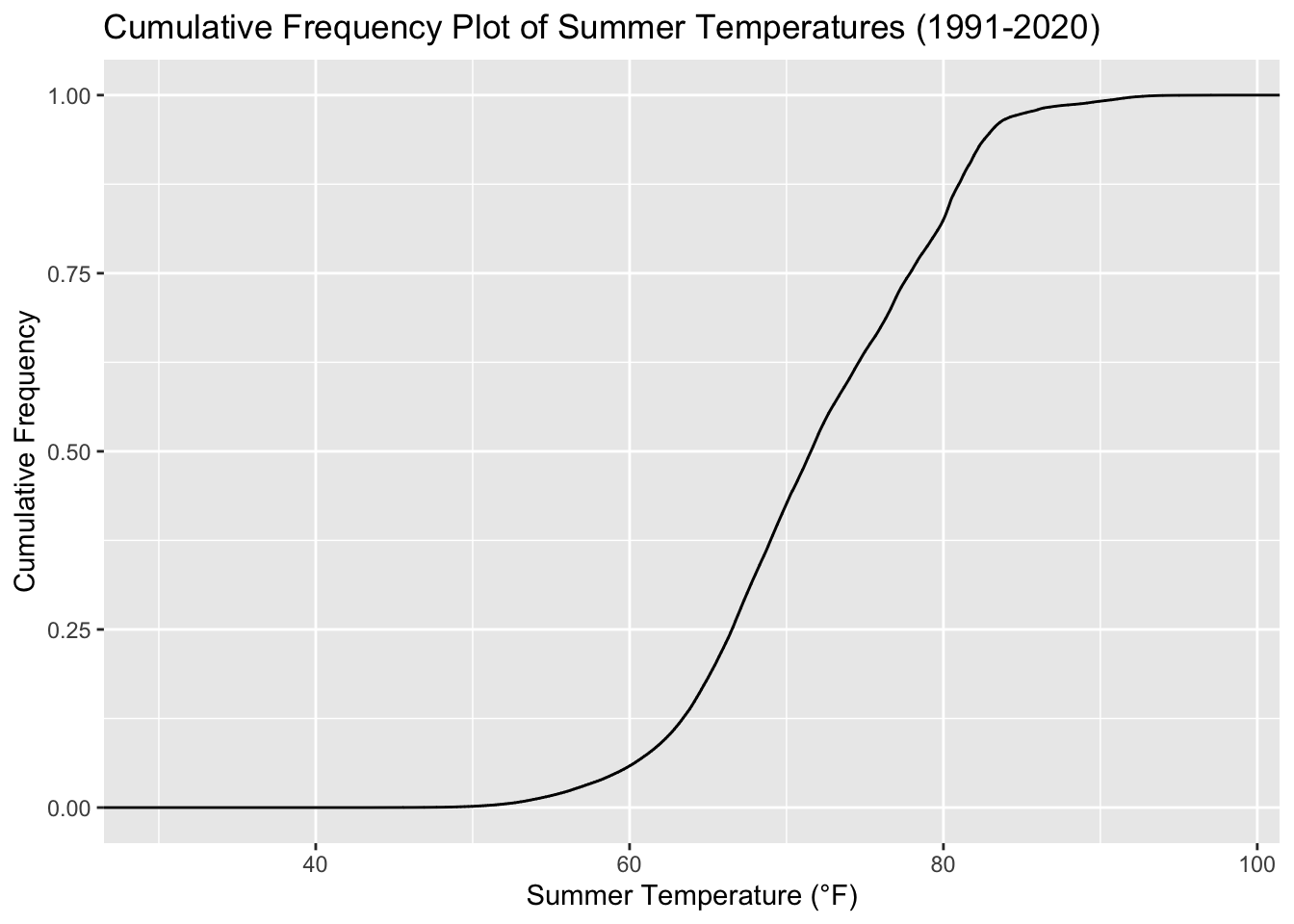
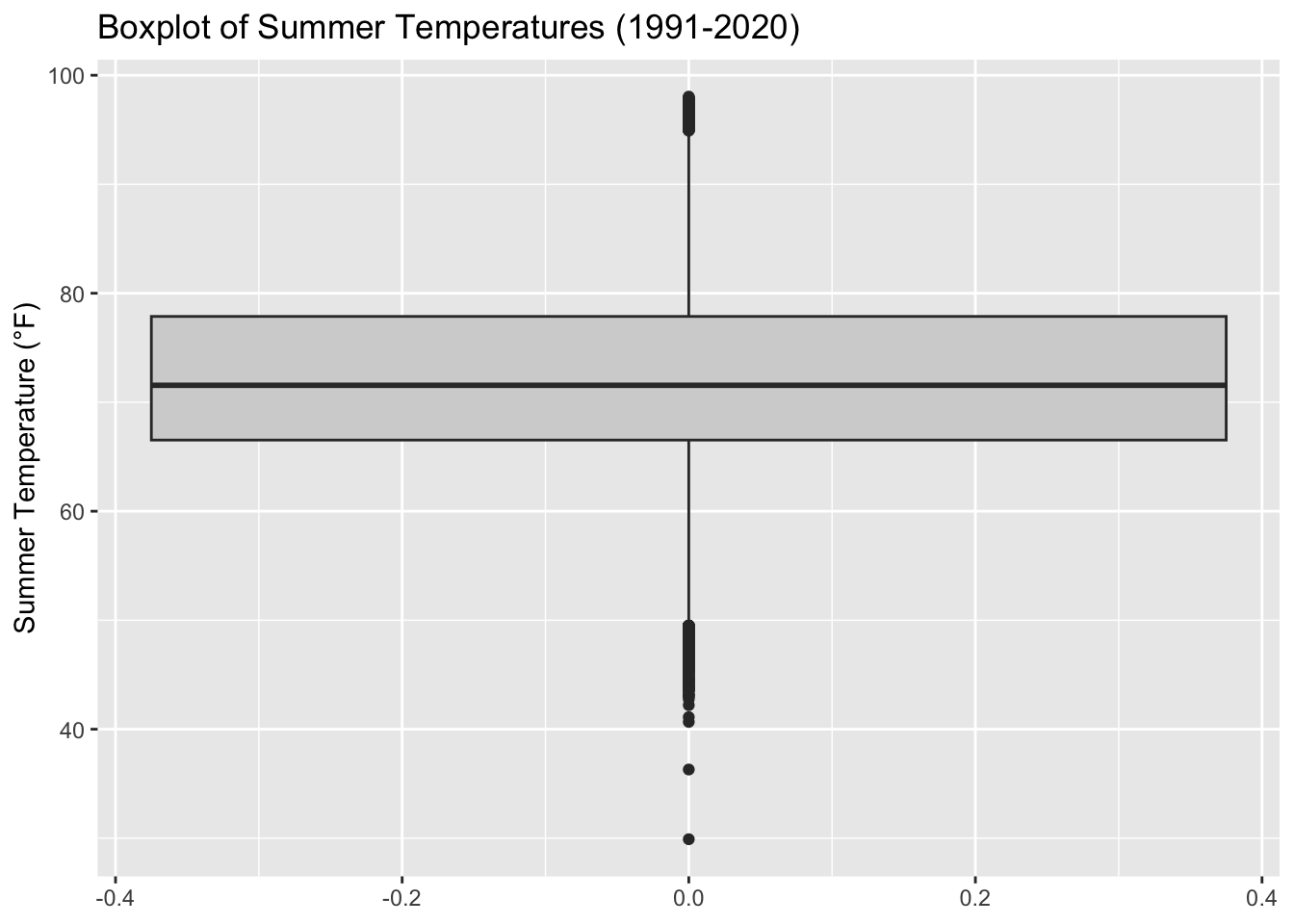
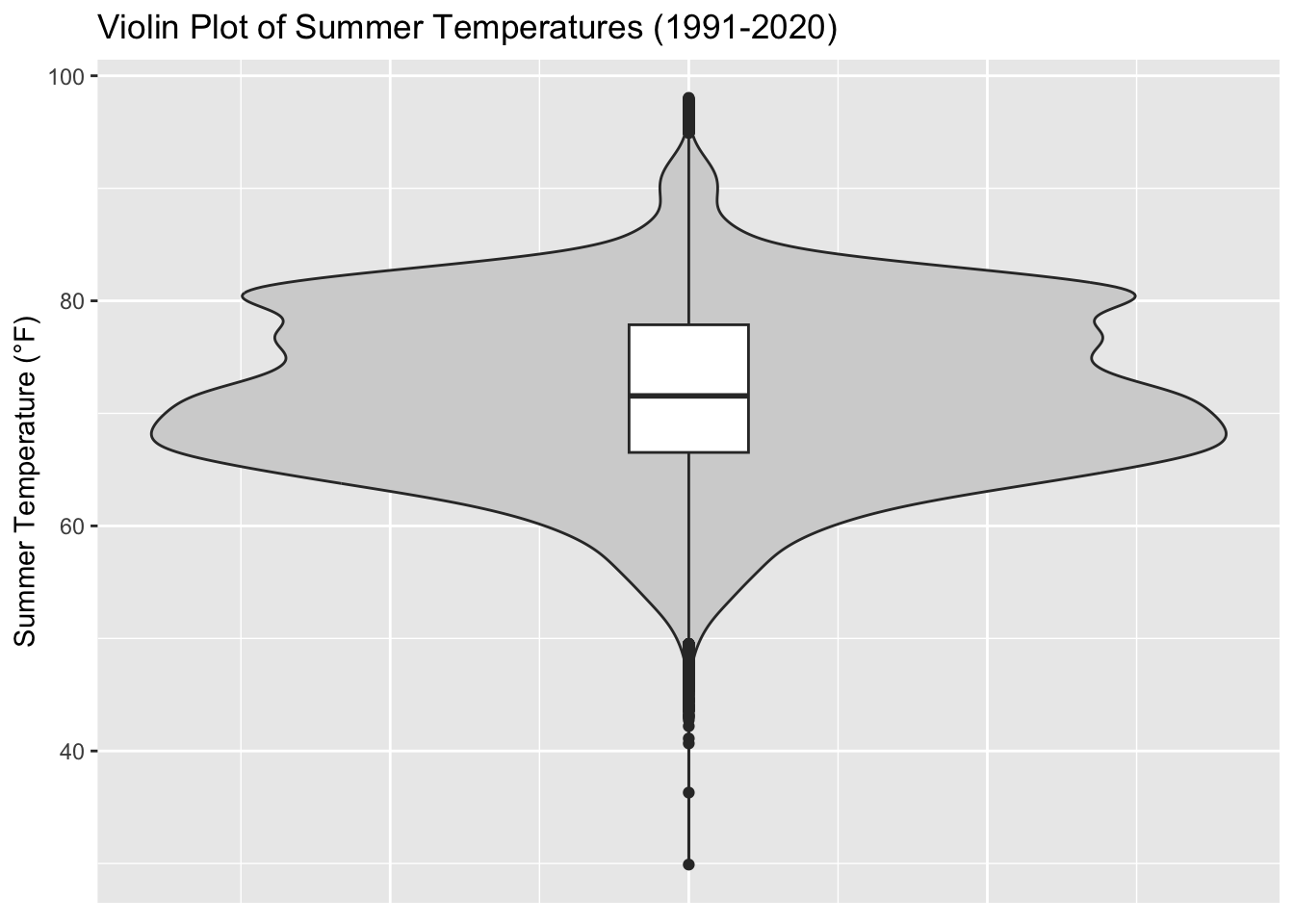
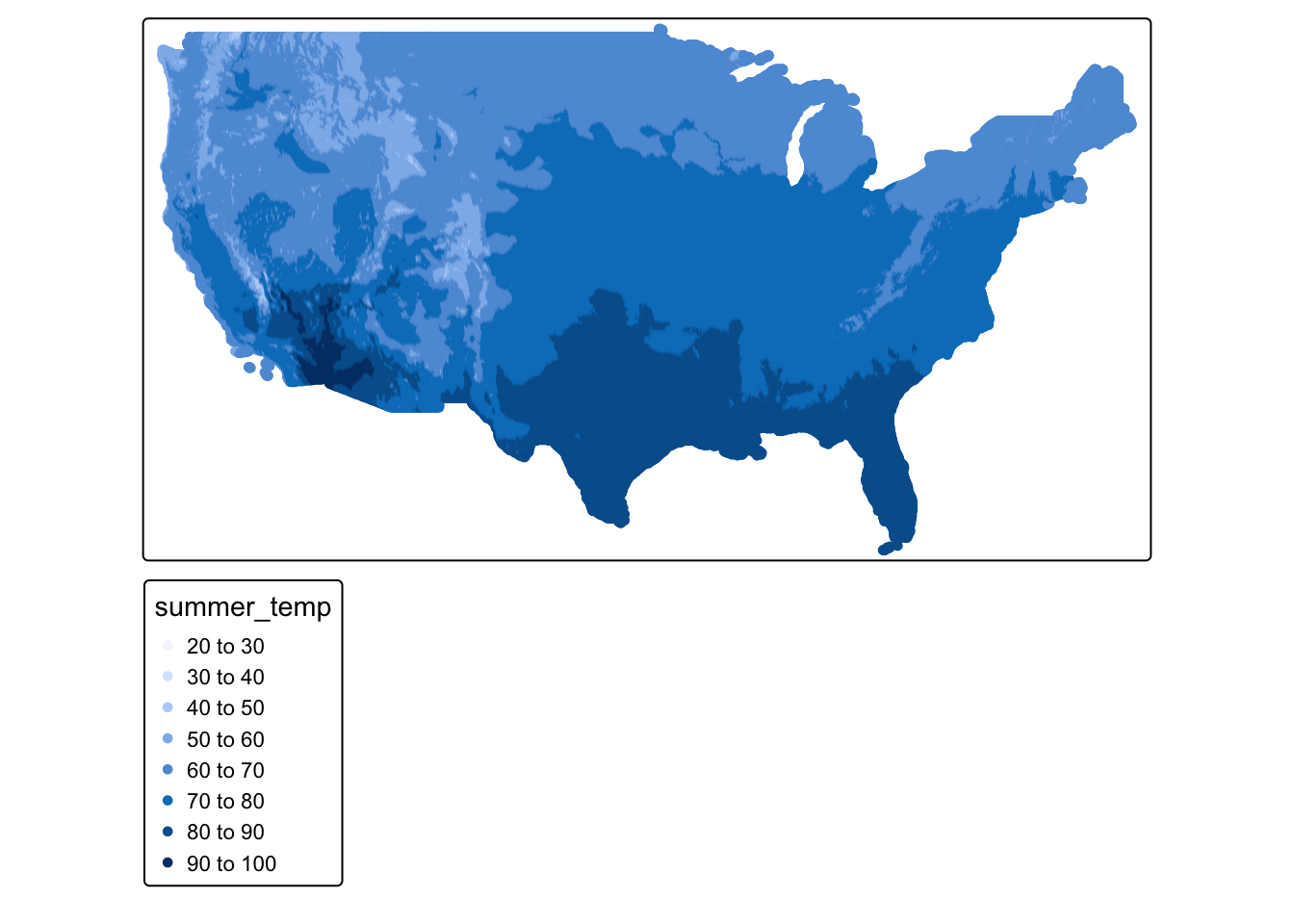
Rows: 2,672
Columns: 54
$ STATEFP <chr> "37", "37", "37", "37", "37", "37", "37", "37", "37",…
$ COUNTYFP <chr> "031", "031", "031", "031", "031", "031", "031", "119…
$ TRACTCE <chr> "970402", "970502", "970805", "970903", "970101", "97…
$ GEOID <chr> "37031970402", "37031970502", "37031970805", "3703197…
$ NAME <chr> "9704.02", "9705.02", "9708.05", "9709.03", "9701.01"…
$ NAMELSAD <chr> "Census Tract 9704.02", "Census Tract 9705.02", "Cens…
$ MTFCC <chr> "G5020", "G5020", "G5020", "G5020", "G5020", "G5020",…
$ FUNCSTAT <chr> "S", "S", "S", "S", "S", "S", "S", "S", "S", "S", "S"…
$ ALAND <dbl> 2395384, 6094915, 139248627, 5864308, 28018671, 97430…
$ AWATER <dbl> 1553995, 4244211, 421209, 30151466, 35773987, 1568180…
$ INTPTLAT <chr> "+34.7239933", "+34.7517653", "+34.7817392", "+34.701…
$ INTPTLON <chr> "-076.7087383", "-076.7387561", "-077.0184797", "-076…
$ tract_name <chr> "Census Tract 9704.02, Carteret County, North Carolin…
$ total_pop <dbl> 1309, 2177, 1694, 1211, 965, 4244, 2306, 2720, 6076, …
$ median_age <dbl> 39.3, 56.1, 43.3, 62.1, 48.4, 55.9, 42.3, 28.3, 29.7,…
$ pct_white <dbl> 64.17, 93.11, 85.36, 85.47, 86.22, 72.64, 72.94, 6.32…
$ pct_black <dbl> 21.01, 2.30, 0.00, 0.66, 3.21, 17.86, 9.71, 45.96, 30…
$ pct_aian <dbl> 0.15, 0.00, 0.41, 0.41, 0.00, 2.00, 0.00, 0.00, 0.05,…
$ pct_asian <dbl> 0.00, 0.00, 1.89, 0.00, 0.00, 0.00, 4.68, 2.90, 1.50,…
$ pct_nhpi <dbl> 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.17, 1.32, 0.00,…
$ pct_other_race <dbl> 0.00, 0.00, 0.00, 0.00, 0.00, 1.06, 0.22, 0.00, 0.00,…
$ pct_two_races <dbl> 12.15, 0.32, 10.68, 12.80, 0.83, 3.79, 8.24, 1.69, 0.…
$ pct_hisp <dbl> 2.52, 4.27, 1.65, 0.66, 9.74, 2.64, 4.03, 41.80, 63.8…
$ pct_family_hh <dbl> 39.31, 64.53, 73.30, 64.78, 65.03, 64.45, 62.60, 61.2…
$ married_fam <dbl> 19.08, 55.75, 55.45, 61.55, 45.08, 55.44, 42.31, 28.3…
$ male_hh <dbl> 3.71, 0.00, 3.81, 0.48, 9.84, 3.64, 2.88, 9.40, 8.66,…
$ female_hh <dbl> 16.52, 8.77, 14.03, 2.75, 10.11, 5.37, 17.40, 23.56, …
$ pct_nonfam_hh <dbl> 60.69, 35.47, 26.70, 35.22, 34.97, 35.55, 37.40, 38.7…
$ nonfam_male_hh <dbl> 37.00, 16.13, 15.26, 14.22, 18.31, 17.25, 13.37, 13.7…
$ nonfam_fem_hh <dbl> 23.69, 19.34, 11.44, 21.00, 16.67, 18.30, 24.04, 25.0…
$ av_hh_size <dbl> 1.64, 2.05, 2.31, 1.96, 2.37, 2.03, 2.21, 3.01, 2.89,…
$ pct_less_hs <dbl> 17.40, 7.95, 9.49, 0.00, 8.64, 18.64, 6.50, 19.05, 29…
$ pct_hs <dbl> 52.21, 53.92, 69.15, 41.87, 67.83, 59.63, 61.34, 60.9…
$ pc_bach <dbl> 30.38, 38.13, 21.36, 58.13, 23.54, 21.73, 32.17, 19.9…
$ pct_unemp <dbl> 5.67, 0.41, 0.86, 1.47, 1.45, 0.13, 0.95, 5.91, 8.52,…
$ med_hh_inc <dbl> 45391, 86583, 66548, 96198, 58750, 67195, 63393, 4844…
$ gini_index <dbl> 0.4094, 0.4039, 0.4377, 0.4689, 0.5036, 0.4248, 0.462…
$ pct_owner <dbl> 41.87, 87.64, 81.47, 86.11, 81.42, 70.29, 62.98, 25.1…
$ pct_renter <dbl> 58.13, 12.36, 18.53, 13.89, 18.58, 29.71, 37.02, 74.8…
$ pct_vacant <dbl> 19.57, 10.09, 18.90, 78.84, 45.29, 14.68, 8.29, 6.22,…
$ med_year_built <dbl> 1962, 1985, 1997, 1988, 1965, 1994, 1984, 1983, 1986,…
$ pct_gas <dbl> 18.95, 13.02, 7.36, 13.41, 31.15, 2.30, 3.56, 49.89, …
$ pct_electric <dbl> 77.21, 85.66, 85.01, 84.81, 53.83, 96.26, 95.67, 49.7…
$ med_house_val <dbl> 234100, 329900, 208800, 669300, 168500, 262600, 23640…
$ med_rent <dbl> 781, 1241, 1133, 1489, 1000, 762, 1184, 1355, 1309, 2…
$ pct_pov <dbl> 26.02, 4.10, 9.63, 4.21, 16.63, 9.50, 18.35, 16.09, 1…
$ pct_drive_work <dbl> 90.34, 89.37, 87.40, 75.43, 78.46, 85.78, 94.20, 86.3…
$ pct_public_trans <dbl> 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 4.12, 3.60,…
$ bike_walk <dbl> 3.22, 0.00, 2.95, 0.00, 2.25, 0.00, 1.40, 2.22, 0.00,…
$ pct_wfh <dbl> 6.44, 7.95, 8.17, 24.57, 8.36, 10.30, 4.12, 5.43, 11.…
$ av_commute <dbl> 17, 20, 26, 28, 32, 17, 23, 19, 25, 24, 25, 23, 25, 2…
$ pct_no_veh <dbl> 27.53, 0.57, 0.00, 3.07, 4.92, 2.97, 3.94, 7.52, 7.90…
$ no_health_insur <dbl> 19.39, 7.21, 15.13, 4.29, 7.85, 16.02, 6.16, 14.72, 4…
$ geometry <MULTIPOLYGON [°]> MULTIPOLYGON (((-76.74294 3..., MULTIPOL…